
Automated News Pipeline
The Client & Their Situation
A daily newsletter publisher covering industry news for professionals in their sector. Their editorial team’s core job is finding and curating the most relevant stories from across the industry. But as the newsletter grew, the process of finding those stories was consuming more time than writing about them.
The Operational Challenge
Every morning, the newsletter team faced the same grind: visit dozens of websites, scan for relevant articles, copy links into a spreadsheet, check if they had already covered the story, and repeat. It was slow, inconsistent, and impossible to scale.
As the newsletter curator described it: “Curating the newsletter meant manually checking 30+ websites multiple times a day, constantly searching for fresh stories across sectors and markets. It was extremely time-consuming and fragmented, and I was essentially hunting for news all day.”
The real cost was not just time. Without a systematic way to track coverage, articles slipped through. Some sources got checked daily while others were forgotten for weeks. There was no way to know what they were missing or to apply consistent criteria across hundreds of potential sources.
The team knew what good content looked like. They just could not see it all in one place.
The Strategic Thinking
The obvious solution would have been to build a scraper that dumped articles into a database. But that would have created a new problem: a firehose of unorganized content that still required manual sorting.
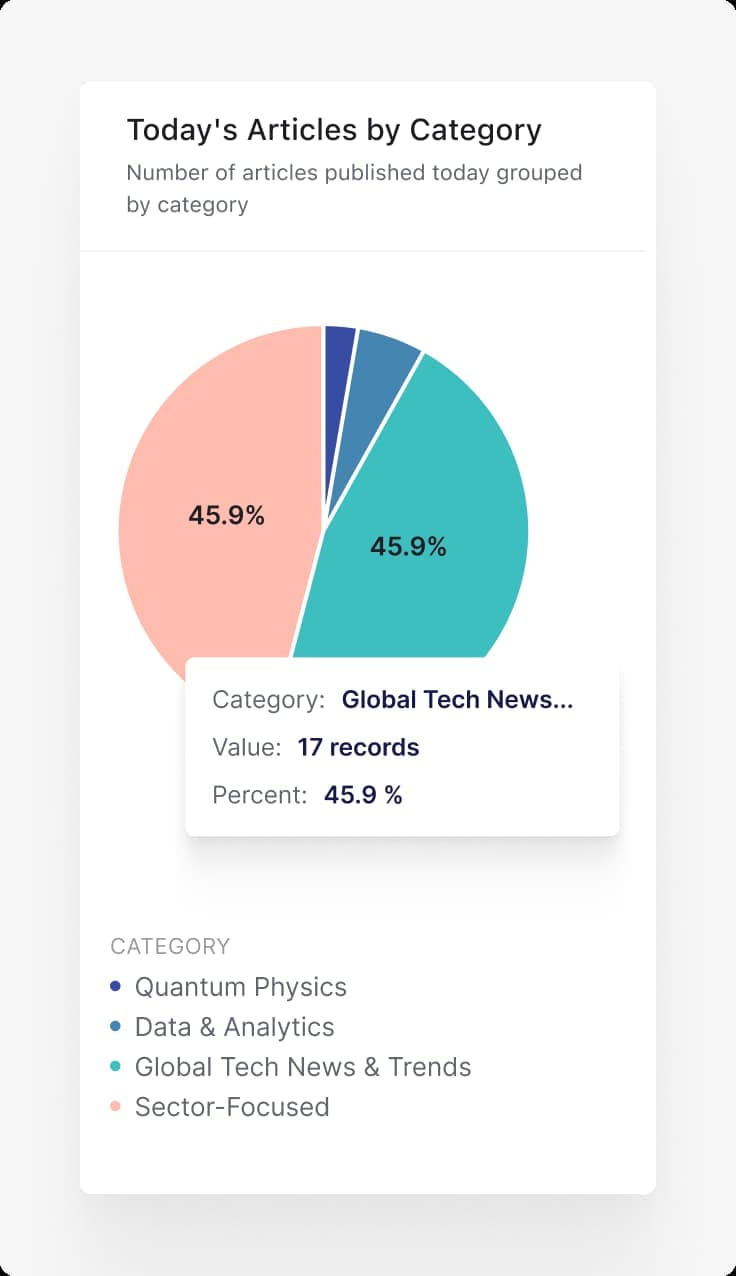
We reframed the goal. The newsletter team did not need more articles. They needed a dashboard where all relevant content appeared, already organized by the categories they cared about, with duplicates removed and low-quality sources filtered out. The infrastructure should be invisible. The output should feel like opening a well-organized inbox.
This shaped every decision:
Dashboard-first design. We started with how the editorial team wanted to browse content: by sector, market, date, and source quality. The technical architecture worked backward from that interface.
Validation at multiple gates. Rather than dumping everything into the dashboard and letting the team sort through garbage, we built validation rules that caught sponsored content, duplicate links, articles with missing dates, and stale content before it ever reached the team.
Configuration over code. We stored source metadata in a spreadsheet rather than hardcoding it. This meant the team could add new sources, adjust classifications, or disable problematic crawlers without waiting for a developer.
Modular stages for debugging. When you are collecting from hundreds of sources, things break constantly. We designed the pipeline so each stage could fail independently without taking down the whole system, and so the team could see exactly where articles were being dropped and why.
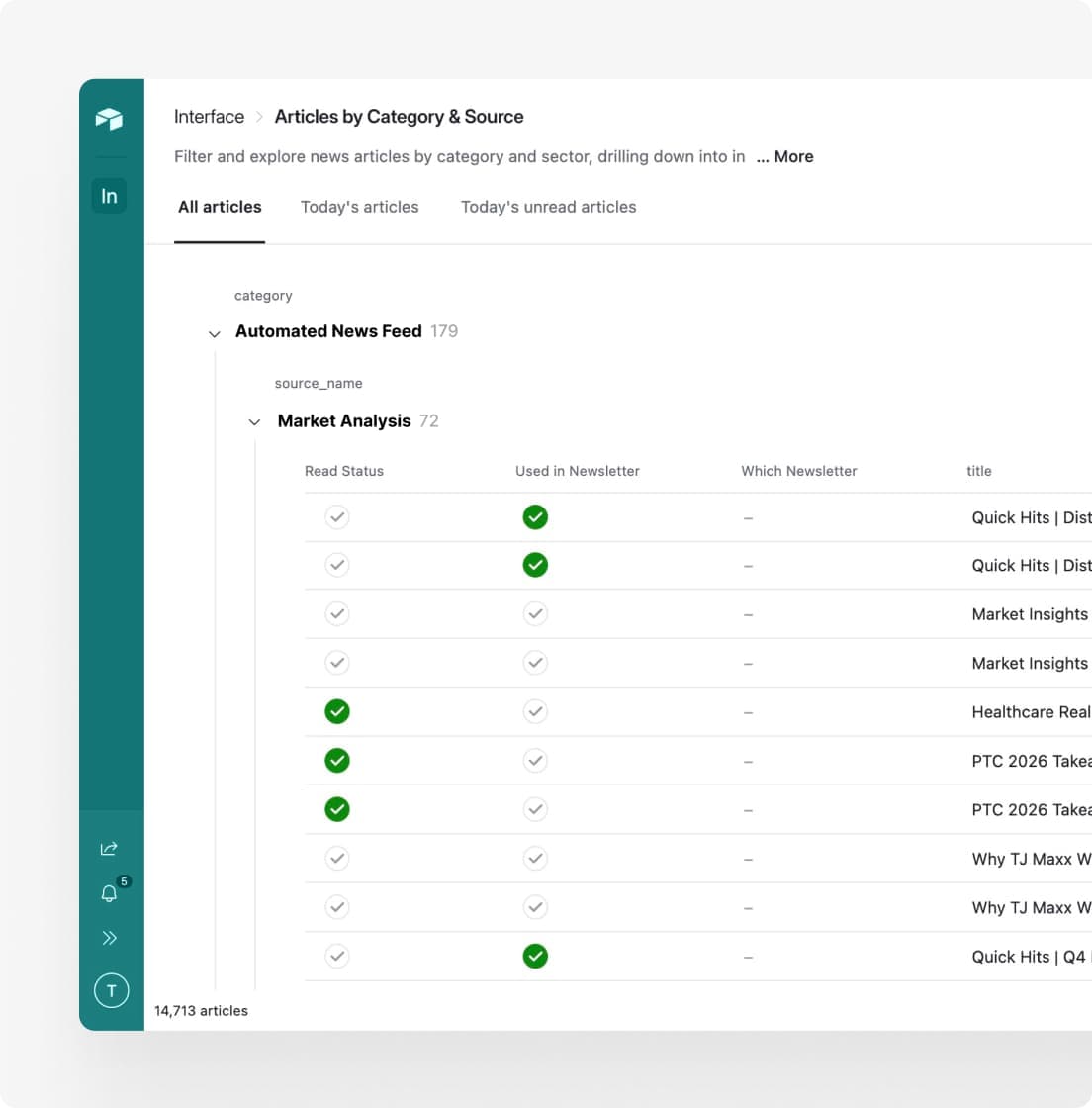
What We Built
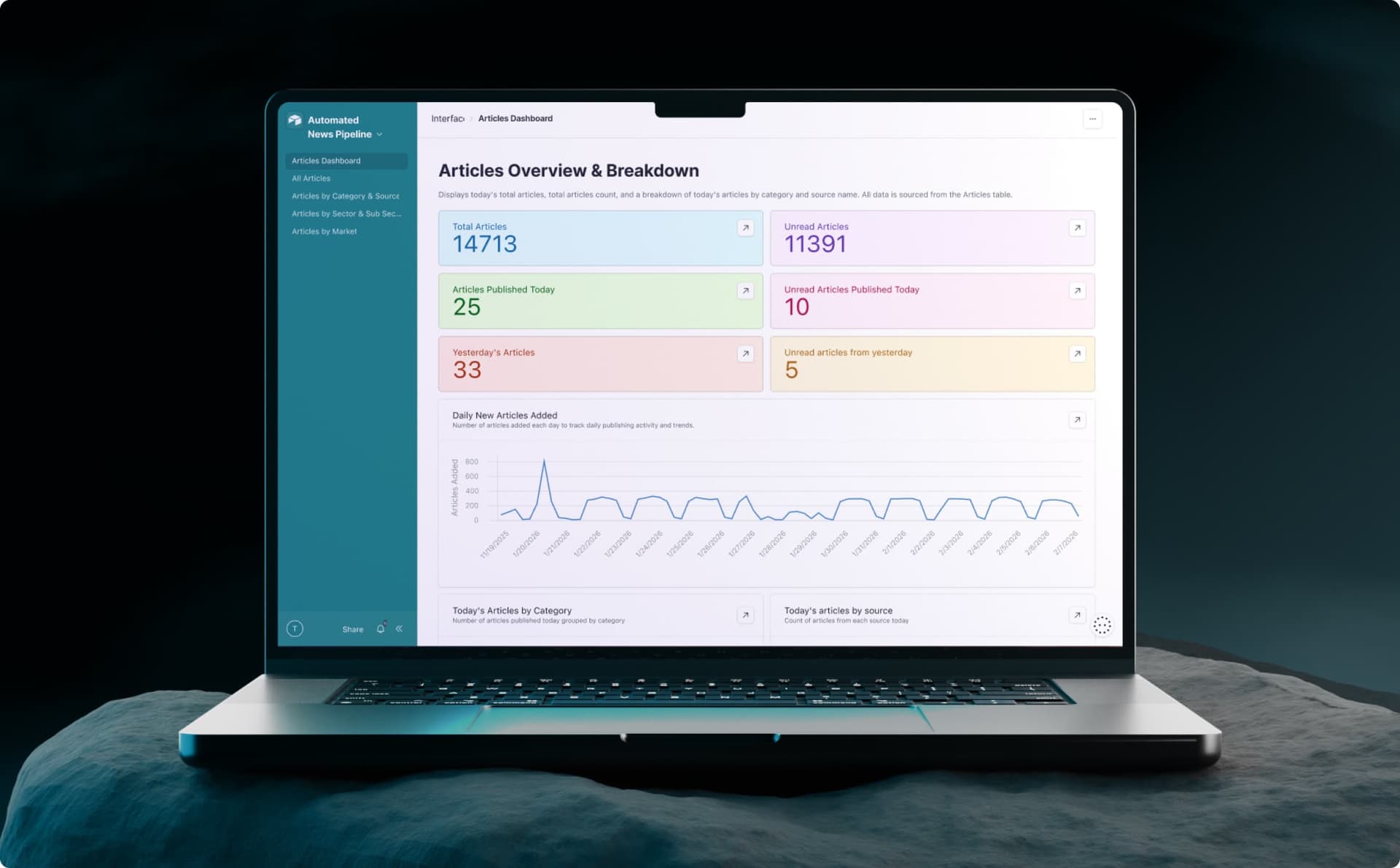
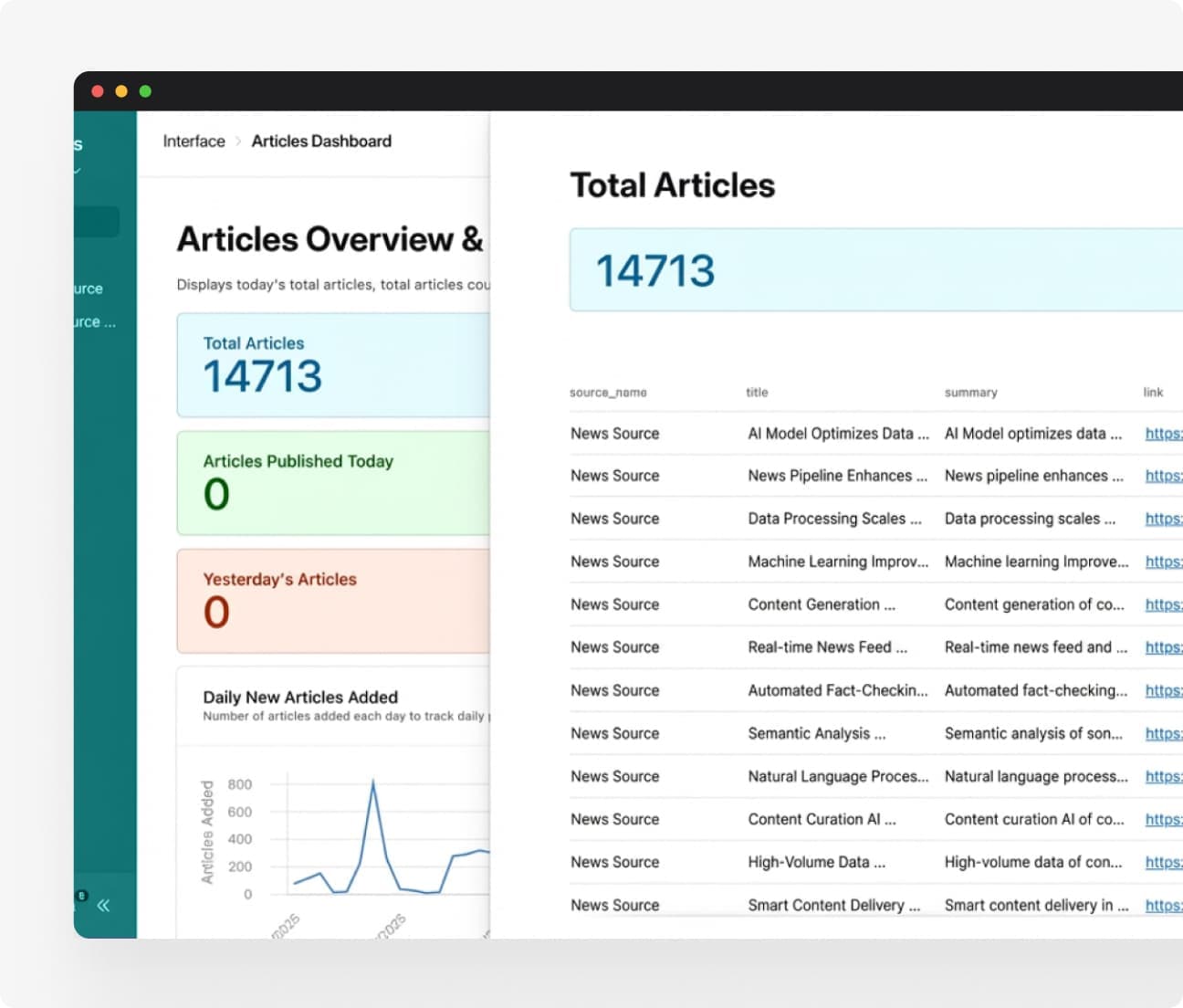
An automated article collection system that crawls hundreds of sources, normalizes and validates the data, and delivers clean content to a searchable dashboard.
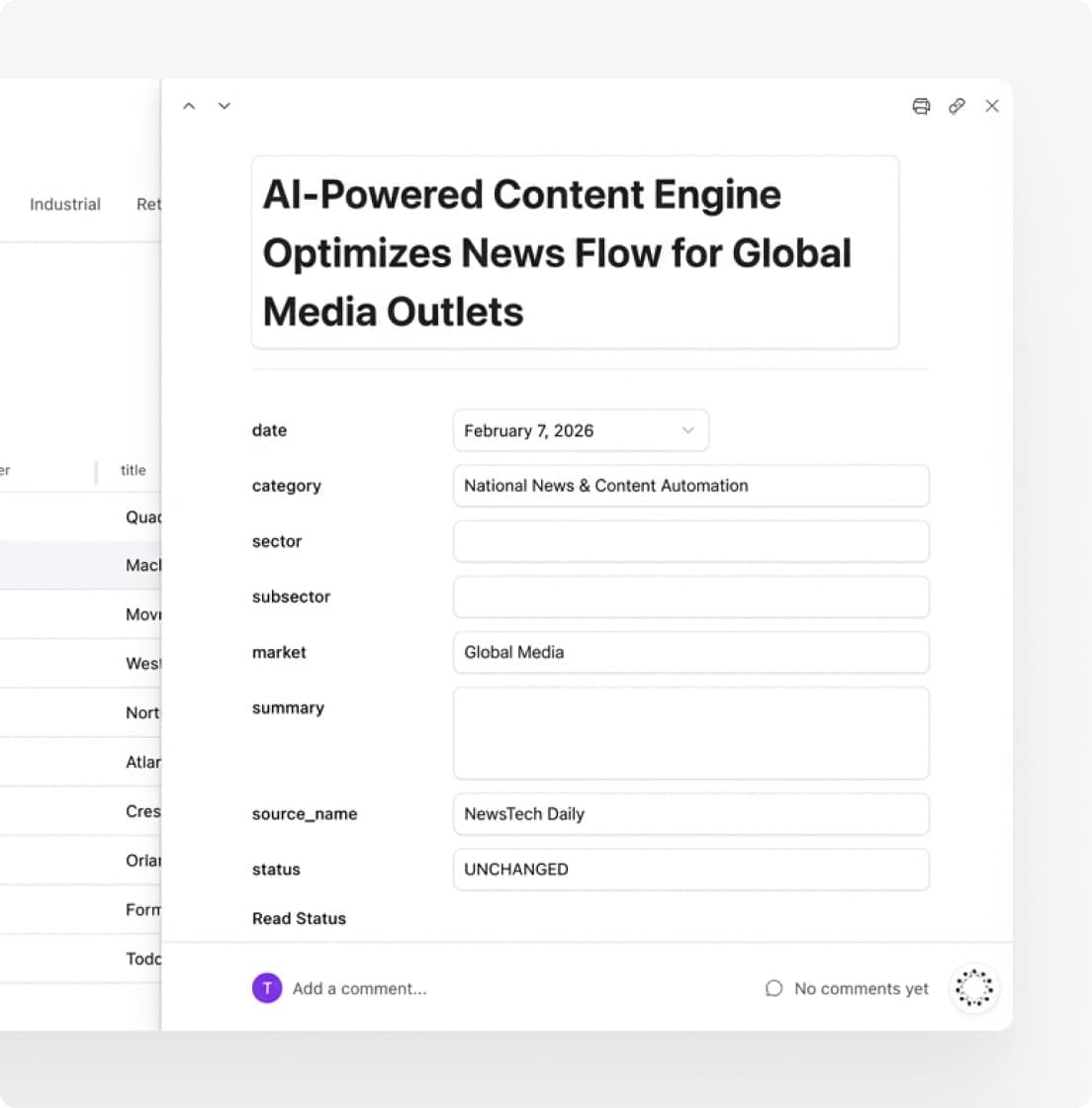
Scheduled jobs fetch fresh content from configured sources throughout the day. A centralized spreadsheet stores source URLs and classification metadata. Custom extraction logic normalizes URLs and enriches articles with category tags relevant to the publisher’s coverage areas.
The validation pipeline enforces required fields, parses dates into a consistent format, filters sponsored content, checks for freshness, and runs intelligent deduplication. Automated error notifications alert the team when crawlers fail. Everything that passes validation lands in a dashboard where the editorial team can sort, filter, and mark articles for inclusion.
The tool has completely changed our workflow by aggregating all of our core sources in one place and refreshing them automatically throughout the day. Filtering by category, topic, publish date, and more makes it incredibly easy to surface the right stories in minutes rather than hours. What used to take a significant portion of my day is now a fast, focused task, freeing up time for higher-value editorial and strategic work.
— Newsletter Curator
The Transformation
The newsletter team no longer visits dozens of websites every morning. They open one dashboard.
All available content appears in a single organized view. They can sort by category, filter by topic, scan by date, and mark articles for inclusion without leaving the interface. Articles that do not meet quality criteria never appear in the first place.
The system currently collects from 500+ sources. Adding new sources requires updating a spreadsheet row, not rebuilding infrastructure. When the team wants to expand coverage to a new topic area, they configure the source and the pipeline handles the rest.
Hours of manual browsing have been replaced with minutes of focused curation. The team can now spend their time on what they are good at: understanding which stories matter to their readers and writing about them clearly.

NudFud

Let's talk
If you're building something and need the right partner, schedule a conversation.